SVDQuant
特别感谢 DeepSeek 和 claude code,没有你们很多东西我都会因为不想手打而放弃。
我认真读SVDQuant的代码应该也最少有两次了,想着应该留下一些痕迹。第一次读的时候我还不太搞得懂 forward 是怎么一回事,现在再读已经是为了给推理引擎的feature做准备了。从还在读大四的实习生大模型小白到开始掌握 ai infra入门的正式员工,都时不时接触这个项目,还挺感慨的。
这里写下的内容是我在接触量化过程中的迷惑,没有很严格的数学推理和很多的公式。
前置: 什么是量化?
令人惊讶的是网上居然很少有这方面科普类的文章,比如一文带你读懂什么是模型量化,甚至连 ai 生成的水文也比较少(可能是我搜索的关键词不太对)。总之 Quantization 是一门广泛使用且基础的模型轻量化技术。我不打算写的很详细。
详细的可以看看 “Working with Quantized Types”
和目前针对大模型进行量化的方法有哪些? - 吃果冻不吐果冻皮的回答 - 知乎
RTN量化
我觉得最能体现量化核心思想的是RTN量化(Round-To-Nearest):
- 找到未量化
X:Tensor的最小值 $X_{min}$ 和最大值 $X_{max}$ - 根据量化精度 $Q$ 计算 scale 和 zero point
对于对称量化(zero point = 0):
\[X_{quantized} = round\left(\frac{X}{scale}\right)\] \[X_{dequantized} = X_{quantized} \times scale\]对于非对称量化:
\[X_{quantized} = clamp\left(round\left(\frac{X}{scale} + zero\text{_}point\right), Q_{min}, Q_{max}\right)\] \[X_{dequantized} = (X_{quantized} - zero\text{_}point) \times scale\]其中:
- $scale = \frac{X_{max} - X_{min}}{Q_{max} - Q_{min}}$,
dtype与量化前的X一致 - $\text{zero_point} = round\left(Q_{min} - \frac{X_{min}}{scale}\right)$
- $Q_{min}$ 和 $Q_{max}$ 是量化后的精度范围,如
torch.int8为[-128,127] - $clamp(x, min, max)$ 操作将 $X$ 限制在 $[min, max]$ 范围内
不难理解为什么量化会得到 X_q 和 scale_X,因为量化实际上就是将一个高精度范围(推理的精度通常为torch.bfloat16)映射到一个低精度范围(torch.int8, torch.fp8, torch.int4…)内,而高精度范围会比低精度范围大,所以需要一个比例来将低精度范围放大,这样才能保证量化前后的数值正确——至少在可容忍的误差范围内。
对 X 来说,如果我们选择只对权重 W 量化,就是所谓的weight-only quantization,如果我们对激活A 和权重 W 都量化,就是所谓的weight-activation quantization。例如我们只将权重量化为 4bit,我们就把它叫做W4A16,如果权重和激活都量化成 4bit,就叫做W4A4。
对于步骤 1 来说,我们如何选择最值,是选择整个 tensor(per-tensor)的最值,还是选择矩阵中每一行的最值(per-channel),就是所谓的量化粒度,从直觉上来说粒度当然是越细越好。除了 per-tensor 和 per-channel 的粒度选择外,还有一种折中方案是 分组量化(per-group quantization)。在分组量化中,我们将 tensor 分成多个小组,在每个小组内部独立计算量化的缩放因子(scale)和零点(zero_point)。这个分组的大小由 group size 参数控制。例如,对于一个有 4096 个通道的权重矩阵,我们可以选择每 128 个通道为一组(group_size=128),这样既比 per-tensor(粒度最粗)更精细,又比 per-channel(粒度最细)计算开销更小。分组量化在精度和效率之间提供了一个灵活的可调节点。我在学习过程中所见使用最多的应该就是per-group,group_size往往能够被作为参数传入,所以量化后衡量模型好坏再反过来调整量化参数也很重要,当然 group_size在某些情况下不能为某些值,以后遇到报错会知道的。
对于步骤 2 来说,我们选择的量化精度实际上是需要根据推理运行的硬件来选择的,例如英伟达 4090 显卡支持 fp8 计算,而 3090 Tensor Core 不支持fp8, 推理速度可能和 bf16 差不多。
当然除了权重与激活以外,还有KV cache量化,但我是做diffusion model的,完全不熟悉这个,就不写了。
接下来稍微仔细一点地说明为什么需要在意量化粒度与量化精度,以及为什么一个单纯的模型权重可以被量化激活。
为什么要在意量化粒度?
这个问题其实可以拆分成两个小问题:
- 为什么量化粒度越小精度越高?
- 为什么量化的粒度不是越小越好?
为什么量化粒度越小精度越高
虽然我不喜欢讲一个问题前先引入一个新的概念,但还是先介绍一下outlier。
outlier在牛津词典中的解释是 n.异于一般的人或物、远离某主要部分的地方。这里主要取第二个意思,指离群值,也就是权重的数值分布中极端大或极端小的数值,见下图(a)左。
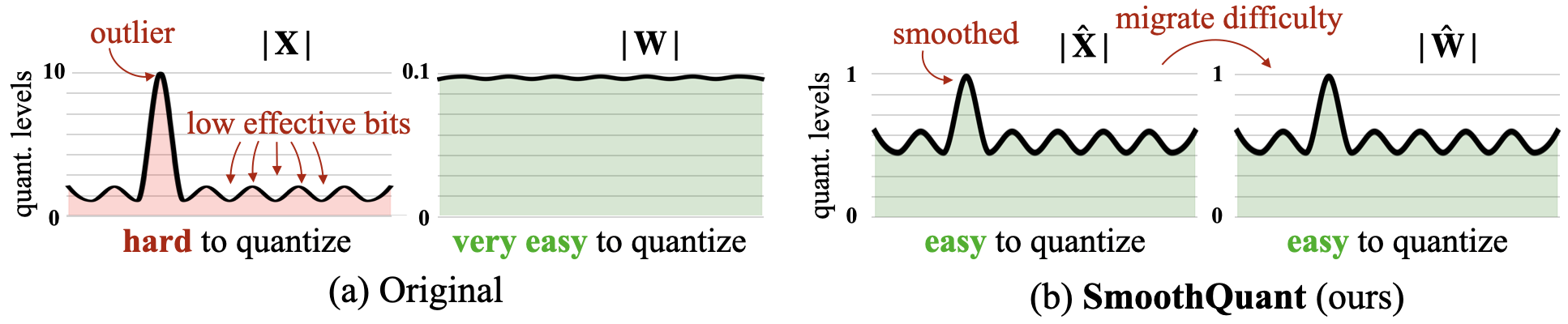
量化中最重要的参数是scale,它决定了量化分辨率(能表示的最小变化)。对于对称量化:
当存在outlier时,$\max(\vert X \vert)$ 会被拉大,导致所有值的量化分辨率变粗。以per-tensor量化为例,一个outlier会影响整个tensor的量化精度。
量化误差可以用均方误差 MSE 表示:
\[Err = \frac{1}{n}\sum_{i=1}^{n}(X_i - \text{round}\left(\frac{X_i}{scale}\right) \times scale)^2\]其中$X_i$是原始权重,$round(\cdot)$ 是四舍五入到量化精度的操作。当$scale$被outlier拉大时,$round\left(\frac{X_i}{scale}\right)$ 的分辨率降低,导致量化误差$Err$增大。
因此 scale 越大,Err 越大。当量化粒度较小时,受到 outlier 影响的权重越少,量化精度相对粗粒度量化更高。
为什么量化粒度不是越小越好
最开始我以为这个问题是站在memory 角度解决的,毕竟如果是 per weight量化,实际上得到的 X_q( low bits) + scale (hight bits) > X (high bits)。但仔细一想根本没有 per weight 量化,即使是对于粒度最细的per-channel 来说,额外的 scale 和 zero_point开销也是很小的,这一点说不通。
直觉上我感觉这和CUDA 等硬件优化有关,例如grouped_gemm,如果group_size太小,会影响到批处理 gemm 的效率。但我没有具体地查证与验证过,再此先记录一下吧。
如何决定量化精度?
- 硬件是否支持对应精度,例如 Tensor Core
- 精度损失容忍度
- 内存限制:假如我想用 5090 跑 qwen image(20B),至少得把它量化到 8bit 才能在 32g的显存内塞下它。
- 量化算法:有的
W4A4算法比FP8精度还好,有现成的优秀算法当然是越低 bit 越好。
如何去量化激活?
我觉得讲解这个问题前,应该先知道激活是什么。我想读到这里的人应该至少对模型推理的过程至少有一个模糊的认识了。
以FLUX 为例,它的模型结构如下:
点击展开/收起FLUX模型架构
Flux(
(pe_embedder): EmbedND()
(img_in): Linear(in_features=64, out_features=3072, bias=True)
(time_in): MLPEmbedder(
(in_layer): Linear(in_features=256, out_features=3072, bias=True)
(silu): SiLU()
(out_layer): Linear(in_features=3072, out_features=3072, bias=True)
)
(vector_in): MLPEmbedder(
(in_layer): Linear(in_features=768, out_features=3072, bias=True)
(silu): SiLU()
(out_layer): Linear(in_features=3072, out_features=3072, bias=True)
)
(guidance_in): MLPEmbedder(
(in_layer): Linear(in_features=256, out_features=3072, bias=True)
(silu): SiLU()
(out_layer): Linear(in_features=3072, out_features=3072, bias=True)
)
(txt_in): Linear(in_features=4096, out_features=3072, bias=True)
(double_blocks): ModuleList(
(0-18): 19 x DoubleStreamBlock(
(img_mod): Modulation(
(lin): Linear(in_features=3072, out_features=18432, bias=True)
)
(img_norm1): LayerNorm((3072,), eps=1e-06, elementwise_affine=False)
(img_attn): SelfAttention(
(qkv): Linear(in_features=3072, out_features=9216, bias=True)
(norm): QKNorm(
(query_norm): RMSNorm()
(key_norm): RMSNorm()
)
(proj): Linear(in_features=3072, out_features=3072, bias=True)
)
(img_norm2): LayerNorm((3072,), eps=1e-06, elementwise_affine=False)
(img_mlp): Sequential(
(0): Linear(in_features=3072, out_features=12288, bias=True)
(1): GELU(approximate='tanh')
(2): Linear(in_features=12288, out_features=3072, bias=True)
)
(txt_mod): Modulation(
(lin): Linear(in_features=3072, out_features=18432, bias=True)
)
(txt_norm1): LayerNorm((3072,), eps=1e-06, elementwise_affine=False)
(txt_attn): SelfAttention(
(qkv): Linear(in_features=3072, out_features=9216, bias=True)
(norm): QKNorm(
(query_norm): RMSNorm()
(key_norm): RMSNorm()
)
(proj): Linear(in_features=3072, out_features=3072, bias=True)
)
(txt_norm2): LayerNorm((3072,), eps=1e-06, elementwise_affine=False)
(txt_mlp): Sequential(
(0): Linear(in_features=3072, out_features=12288, bias=True)
(1): GELU(approximate='tanh')
(2): Linear(in_features=12288, out_features=3072, bias=True)
)
)
)
(single_blocks): ModuleList(
(0-37): 38 x SingleStreamBlock(
(linear1): Linear(in_features=3072, out_features=21504, bias=True)
(linear2): Linear(in_features=15360, out_features=3072, bias=True)
(norm): QKNorm(
(query_norm): RMSNorm()
(key_norm): RMSNorm()
)
(pre_norm): LayerNorm((3072,), eps=1e-06, elementwise_affine=False)
(mlp_act): GELU(approximate='tanh')
(modulation): Modulation(
(lin): Linear(in_features=3072, out_features=9216, bias=True)
)
)
)
(final_layer): LastLayer(
(norm_final): LayerNorm((3072,), eps=1e-06, elementwise_affine=False)
(linear): Linear(in_features=3072, out_features=64, bias=True)
(adaLN_modulation): Sequential(
(0): SiLU()
(1): Linear(in_features=3072, out_features=6144, bias=True)
)
)
)
前置:Smoothquant
关联阅读:“From SmoothQuant to SVDQuant”
这一篇博客和我不同,他主要是论文的概述,推论的很清晰且不细节。
SVDquant
svdquant 是在 smoothquant 后续的工作。顺带一提 smoothquant 后续有非常多有名的量化工作,例如 AWQ。 在svdquant作者的实现